
CRISP-DM for AI Engineering: Why a 1996 Framework Still Describes Modern AI Development
See how CRISP-DM still guides AI engineers in 2026, translating each phase into practical workflows for LLM apps, RAG pipelines, and production AI systems.
During AI development, teams work with large language models (LLMs), build agents with Retrieval-Augmented Generation (RAG) and the Model Context Protocol (MCP), experiment with prompts, design evaluation pipelines, and deploy systems to production.
At first glance, this ecosystem of tools and techniques seems entirely new.
However, much of the underlying workflow mirrors the practices that emerged in data projects in the 1990s and formalized in a framework called CRISP-DM (Cross-Industry Standard Process for Data Mining).
In this article, we'll show why and how CRISP-DM still applies to AI engineering systems.
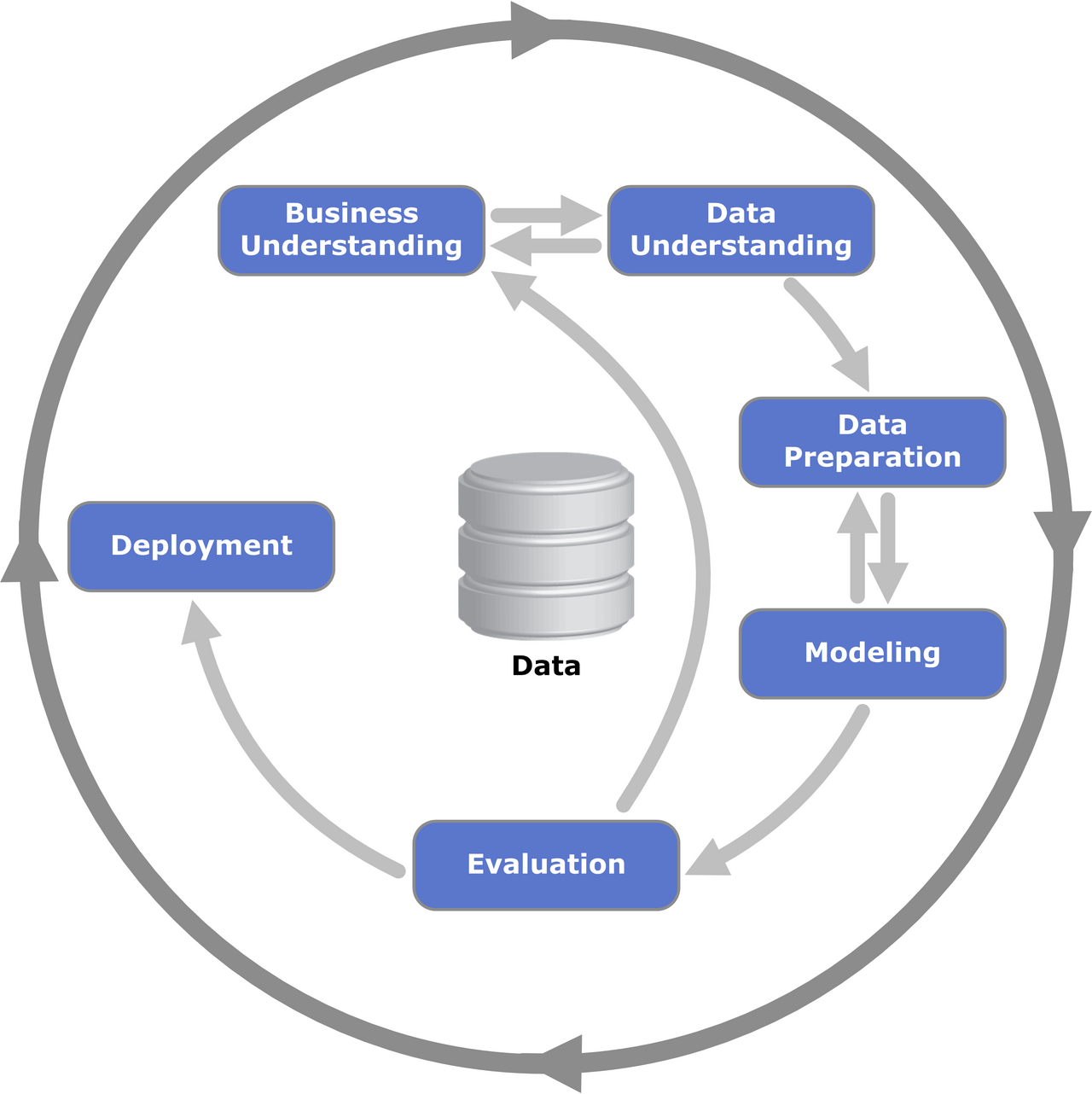
What CRISP-DM Is
CRISP-DM (Cross-Industry Standard Process for Data Mining) is a project methodology for building data-driven systems.
In the early and mid-1990s, the term “data science” did not yet exist. Teams working with data usually referred to their work as data mining, analytics, or statistical modeling. Although many projects followed similar stages, these workflows were typically informal and organization-specific.
CRISP-DM was created in 1996 by a consortium of three companies active in the emerging data mining industry: Daimler-Benz, SPSS, and NCR Corporation, with support from the European Commission.
They envisioned CRISP-DM as a framework that would consolidate and standardize the common practices used in data mining projects and define a process that could work across industries, tools, and applications.
The final specification, developed through collaboration with a broader group of practitioners and tested on real-world projects, was published in 1999 as CRISP-DM 1.0: Step-by-step data mining guide.
Why CRISP-DM Still Matters for AI Engineering: Traditional ML Systems vs. AI Systems
Although CRISP-DM was originally designed for data mining projects and then actively adopted by the data science community, its core ideas still map closely to how modern AI systems are developed.
The table below compares how each CRISP-DM phase typically appears in traditional machine learning systems built by data scientists and ML engineers versus AI systems built by AI engineers. This comparison is particularly useful for engineers coming from a traditional machine learning background, where ML workflows provide a familiar baseline for understanding how AI systems are developed.
| CRISP-DM Phase | ML Systems | AI Systems |
|---|---|---|
| Business Understanding | Define prediction target and success metrics. | Define AI-powered product use case and user experience. |
| Data Understanding | Analyze labeled datasets and feature distributions. | Identify documents, images, APIs, tools, and other inputs. |
| Data Preparation | Feature engineering and dataset curation. | Chunking, embeddings, indexing, and tool wiring for agents. |
| Modeling | Train and tune models on structured data. | Prompt design, schema definition, retrieval, and agent behavior. |
| Evaluation | Accuracy, precision, recall, and other ML metrics. | Task success, human feedback, and observable system behavior. |
| Deployment | Model serving and batch/online inference. | End-to-end AI-powered application or service in production. |
While techniques differ, the overall lifecycle remains consistent: define the problem, understand the available data, prepare inputs, experiment with solutions, evaluate results, and deploy the system into production.
This continuity also explains why data scientists often transition effectively into AI engineering roles with additional software engineering skills.
CRISP-DM Phases and How They Apply to AI Systems
| Phase | Key Question | AI Engineering Focus |
|---|---|---|
| 1. Business Understanding | What problem are we solving and how will we measure success? | Define product goals, guardrails, and metrics before choosing models or tooling. |
| 2. Data Understanding | What data (or documents, tools, and APIs) do we actually have? | Inventory data sources, assess quality, and identify gaps that constrain the solution. |
| 3. Data Preparation | How do we turn raw data into reliable inputs? | Clean, transform, and structure inputs for LLMs, RAG pipelines, or agents. |
| 4. Modeling | Which system design works best technically? | Design prompts, schemas, retrieval strategies, and model configs; run experiments. |
| 5. Evaluation | Does this system actually deliver value? | Compare variants with offline test sets and live experiments against business metrics. |
| 6. Deployment | How do we run this safely in production? | Deploy, monitor, and iterate based on real-world signals, looping back to earlier phases. |
CRISP-DM defines six phases that form an iterative cycle: - Business Understanding - Data Understanding - Data Preparation - Modeling - Evaluation - Deployment
We’ll describe each phase of the CRISP-DM process and how it maps to AI systems in the following sections using an example of an online classifieds website called "Simple Sell", a sample project that I created to illustrate the work of an AI Engineer. On this website, users can sell items by creating listings with a title, description, category, and price. Instead of filling in every field manually, we may want to create an AI feature that takes an uploaded photo and automatically suggests these fields for the user to review and confirm.
In machine learning, we would have a classification problem. In the AI case, we upload an image and want to reliably extract the information we need from it.
Phase 1: Business Understanding
The Business Understanding phase identifies the problem the project aims to solve and outlines what success looks like from a business perspective. Teams collaborate with stakeholders to clarify objectives and define success criteria. They also evaluate available resources, identify risks, and determine whether the expected benefits justify the effort. Once the objective is clear, it is translated into technical goals that describe what the system should produce and how success will be measured.
Example: Online Classifieds Platform
In our example with the online classifieds platform, users must fill out a form to create a listing. Suppose user research shows that completing the form takes about five minutes and that many users find the process tedious. As a result, about 15% of users start creating a listing but never finish.
This confirms a problem that affects users and can be measured. The objective may then be defined as reducing the listing creation time from five minutes to one minute. A secondary metric could be a reduction in the abandonment rate from 15% to 5%.
Only after these goals are defined does the team consider possible solutions. One option might be an AI system that extracts listing attributes directly from an uploaded image and automatically fills parts of the form.
Role of the AI Engineer
At this stage, the AI engineer helps evaluate whether AI is the appropriate approach. In some cases, a simpler rule-based system or product redesign may solve the problem more effectively.
Phase 2: Data Understanding
After defining the business objective, the next step is to examine the data that could help solve the problem.
The Data Understanding phase focuses on identifying, collecting, and analyzing the available data sources to determine whether they are suitable for building the system. In CRISP-DM, this involves collecting the initial data, examining its structure and properties, exploring it to identify patterns or relationships, and assessing its quality.
Example: Online Classifieds Platform
In the classifieds example, the goal is to speed up listing creation by automatically extracting attributes from an uploaded image.
During the Data Understanding phase, the team investigates the image data already available in the system. They examine how images are stored, what formats and resolutions are common, and how frequently listings include images. They may also identify common issues such as blurry, rotated, or missing images. The team can also explore related data fields such as listing titles, descriptions, or category labels that might provide additional context for the AI system.
Role of the AI Engineer
During the Data Understanding phase, the AI engineer works with analysts and backend engineers to examine the available data and assess whether it can support the intended feature.
This includes identifying potential data sources, exploring their structure, and understanding their limitations before designing the system.
Phase 3: Data Preparation
Once the available data is understood, the next step is to prepare it for use by the system.
The Data Preparation phase focuses on transforming raw data. In CRISP-DM, this includes selecting relevant data, cleaning data of errors or inconsistencies, constructing useful attributes, integrating data from multiple sources, and formatting it for reliable processing.
This phase often requires the most effort in a project. Data may need to be cleaned, combined with other sources, or transformed before it can be used effectively.
Example: Online Classifieds Platform
In the classifieds example, the system receives an image uploaded by the user when creating a listing.
During the Data Preparation phase, the team ensures that this image can be processed reliably by the AI system. This may involve validating file formats, checking image size and resolution, normalizing orientation, and resizing images if necessary before sending them to the AI service.
The team may also prepare additional context, such as listing categories or user-provided text, and define the structured format for returning extracted attributes.
In some AI applications, preparation can be more complex. For example, recommendation systems or search features may require integrating multiple datasets such as product catalogs, user interactions, or historical listings.
In RAG-based systems or AI agents, preparation may also involve collecting documents, structuring them for retrieval, and ensuring the system can access external services or databases.
Role of the AI Engineer
During the Data Preparation phase, the AI engineer helps design the pipeline that prepares inputs for the AI system.
This includes defining how data is collected, transformed, and passed to the model or AI service. Ensuring that the data pipeline is reliable and reproducible is essential, since the system’s performance depends directly on the quality and consistency of its inputs.
Phase 4: Modeling
Once the data is prepared, the next step is to build and test the system that will solve the problem.
The Modeling phase focuses on designing and evaluating different approaches to achieve the project’s technical goal. In traditional machine learning projects, this typically involves selecting algorithms, splitting data into training and test sets, building models, and comparing their performance. Although this phase is often considered the most exciting part of the project, it is usually much shorter than earlier stages, such as data preparation.
Example: Online Classifieds Platform
In an AI system based on large language models, the process looks different. Instead of training a model from scratch, the team typically relies on an external model API. The focus shifts from model training to system design and prompt behavior.
In the classifieds example, during the modeling phase, the team designs the prompt, defines the expected output schema (for example, using a structured format such as a Pydantic model), and builds tests to evaluate how reliably the system extracts the correct attributes.
The team then runs experiments, collects evaluation examples, and measures performance using technical metrics, such as the frequency with which the extracted attributes match the expected values. Based on these results, the prompt and system configuration are refined iteratively.
Role of the AI Engineer
During the Modeling phase, the AI engineer designs the interaction between the application and the AI model. This includes defining prompts, output schemas, validation logic, and evaluation datasets.
The goal is to build a system that produces reliable outputs under realistic conditions. Iteration is essential at this stage: engineers repeatedly test, measure, and refine the system until it reaches acceptable technical performance before moving to the next phase.
Phase 5: Evaluation
After building the system, the next step is to determine whether it solves the business problem defined at the beginning of the project.
The Evaluation phase focuses on assessing the solution from a business perspective. While the Modeling phase evaluates technical performance, this stage assesses whether the system meets the business success criteria and whether it should proceed to deployment.
The team may proceed to deployment, refine the system through another iteration, or stop the project if the expected value cannot be achieved.
Example: Online Classifieds Platform
In the classifieds example, the team evaluates whether the solution improves the metrics defined earlier. For instance, they may run an A/B test comparing the existing listing workflow with the AI-assisted version and access results against the main success metrics defined in the Business Understanding phase: listing creation time and abandonment rate.
If the results show that the system improves the defined metrics, the team can move toward broader deployment. Otherwise, the team may revisit earlier phases and refine the approach.
Role of the AI Engineer
During the Evaluation phase, the AI engineer helps design and analyze experiments that measure the system’s real-world performance.
This includes setting up evaluation datasets, defining monitoring metrics, and supporting experiments such as A/B tests. The goal is to determine whether the system delivers measurable value in the product environment before committing to full deployment.
Phase 6: Deployment
Once the system has been validated, the final step is to make it available in the production environment.
The Deployment phase focuses on delivering the solution so that users or downstream systems can access its results. CRISP-DM describes several activities in this phase. Teams plan how the system will be deployed, define monitoring and maintenance procedures, document project results, and review the overall process to capture lessons learned.
Example: Online Classifieds Platform
In the classifieds example, deployment means integrating the AI system into the listing creation workflow. When a user uploads an image, the system automatically extracts relevant attributes and pre-fills parts of the listing form.
At this stage, the team ensures that the system works reliably in production. This includes integrating the AI service with the backend, handling errors or unexpected inputs, and monitoring the system’s behavior over time.
Once deployed, the team continues to track the key metrics defined earlier, such as listing creation time and abandonment rate, to ensure the system continues to deliver value.
Role of the AI Engineer
During the Deployment phase, the AI engineer is responsible for integrating the AI system into the production environment.
This may involve building APIs, connecting the system to existing services, and implementing monitoring to track performance, usage, and potential failures. Because AI systems can change in behavior over time or encounter new inputs, ongoing monitoring and occasional adjustments are often required.
Iterative Nature of CRISP-DM
Although CRISP-DM describes deployment as the final phase, the process remains iterative. Insights from production usage may lead the team to revisit earlier phases and improve the system in subsequent iterations.
This iterative approach is essential for AI projects where:
- User behavior may be unpredictable
- Prompts need refinement
- Evaluation metrics may need adjustment
Who Is Involved at Each Phase of the CRISP-DM
CRISP-DM highlights that building data-driven systems is a collaborative process. Different roles contribute at different stages of the lifecycle, although AI engineers are typically involved throughout the entire process.
| CRISP-DM Phase | Primary Roles | What They Do |
|---|---|---|
| Business Understanding | Product managers, AI engineers | Define the problem, business objectives, and success criteria; assess whether AI is the right approach. |
| Data Understanding | Data analysts, product managers, AI engineers, backend engineers | Explore available data, map where it lives, and understand how reliably it can be accessed and used. |
| Data Preparation | Data engineers, AI engineers | Build and maintain pipelines that collect, clean, transform, and structure data for the AI system. |
| Modeling | AI engineers | Design the system, prompts, schemas, and model configurations; run experiments to reach target performance. |
| Evaluation | AI engineers, analysts, product managers | Design and analyze experiments (for example, A/B tests) to see whether the system meets business and user goals. |
| Deployment | AI engineers, platform/infra engineers | Integrate the system into production, monitor it, and ensure it runs reliably in real-world conditions. |
Because AI engineers design, build, and integrate the system, they tend to participate in nearly every stage of the CRISP-DM lifecycle, working closely with product, data, and engineering teams.
Conclusion
As we've seen, CRISP-DM is still relevant for AI engineering today. It provides a structured approach to the development process that can help you build successful AI systems. While the tools change (from training models to API calls), the fundamental process of building data-driven products remains constant.


