
Telegram Writing Assistant: Claude Code Turns Voice Notes Into Markdown
Learn how I built a Telegram-based writing assistant that uses Claude Code to transcribe voice notes and convert brain dumps into structured Markdown, saved and versioned in a GitHub repo.
I work on many projects, and most of the work happens before anything becomes public. This includes early thinking, small experiments, and intermediate workflows that usually disappear once a final result is ready.
That means you can only see the final results of my work: finished projects, talks, or materials. Everything that led to them remains invisible.
As I started this Substack, I realized I want to share my background work too because it’s an important part of what I do. It helps you understand how I approach my projects and, hopefully, gives you new ideas.
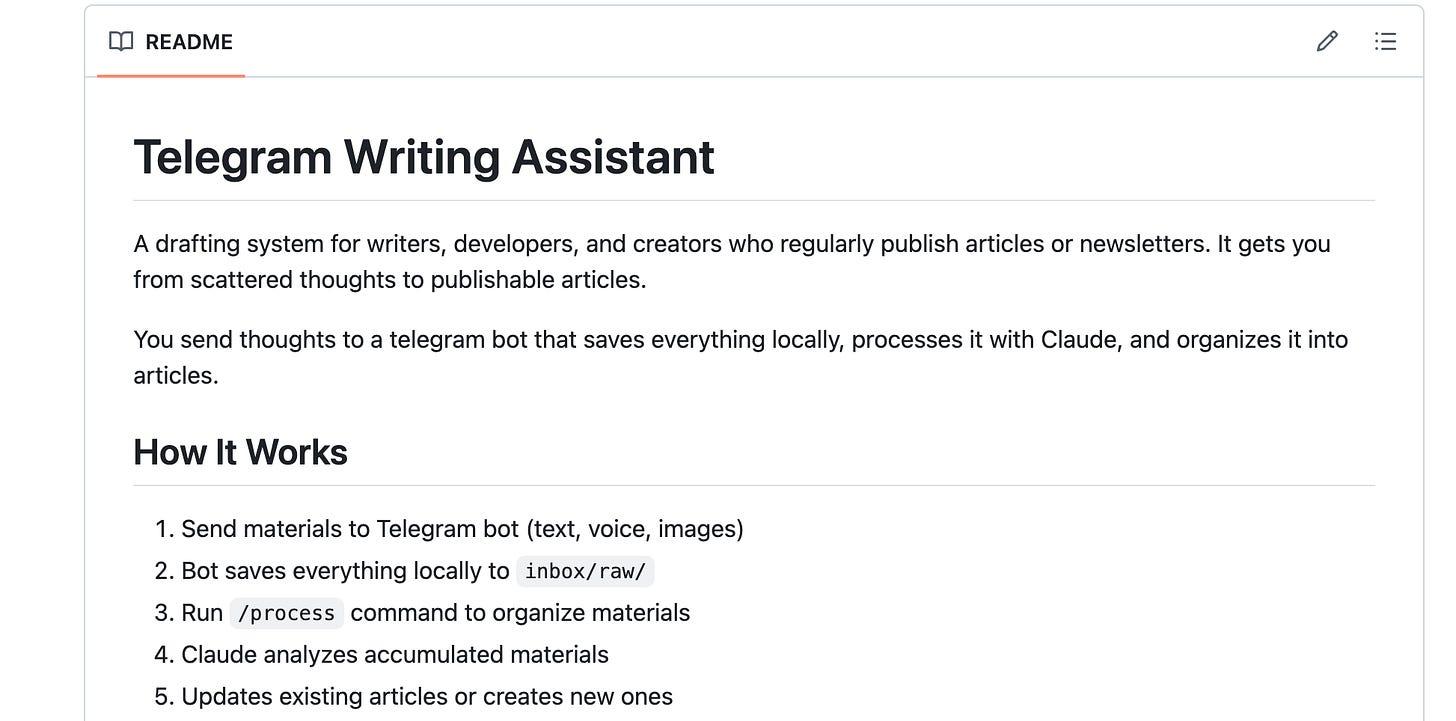
To help myself capture that background work, I built a Telegram-based writing assistant using Claude Code agents. It can process my raw voice notes, files, and text messages into structured articles and store them in a GitHub repository.
I want to explain how I built the system, how it works, and how you can adapt the same approach for your own workflow.
Origin Story
Initially, when I started recording ideas using Telegram as a brain dump, there was no assistant to help me. I just created a new chat for my team and me, and collected my ideas there so we could use them to produce content. That was a great starting point and a key factor in creating the first editions of this newsletter.
But it had one limitation: manual processing. Over time, my Telegram became overloaded with voice notes that quickly piled up into a long, unstructured list of raw materials. Some pieces belonged to the same topic. Others were partial thoughts, corrections, or follow-ups.
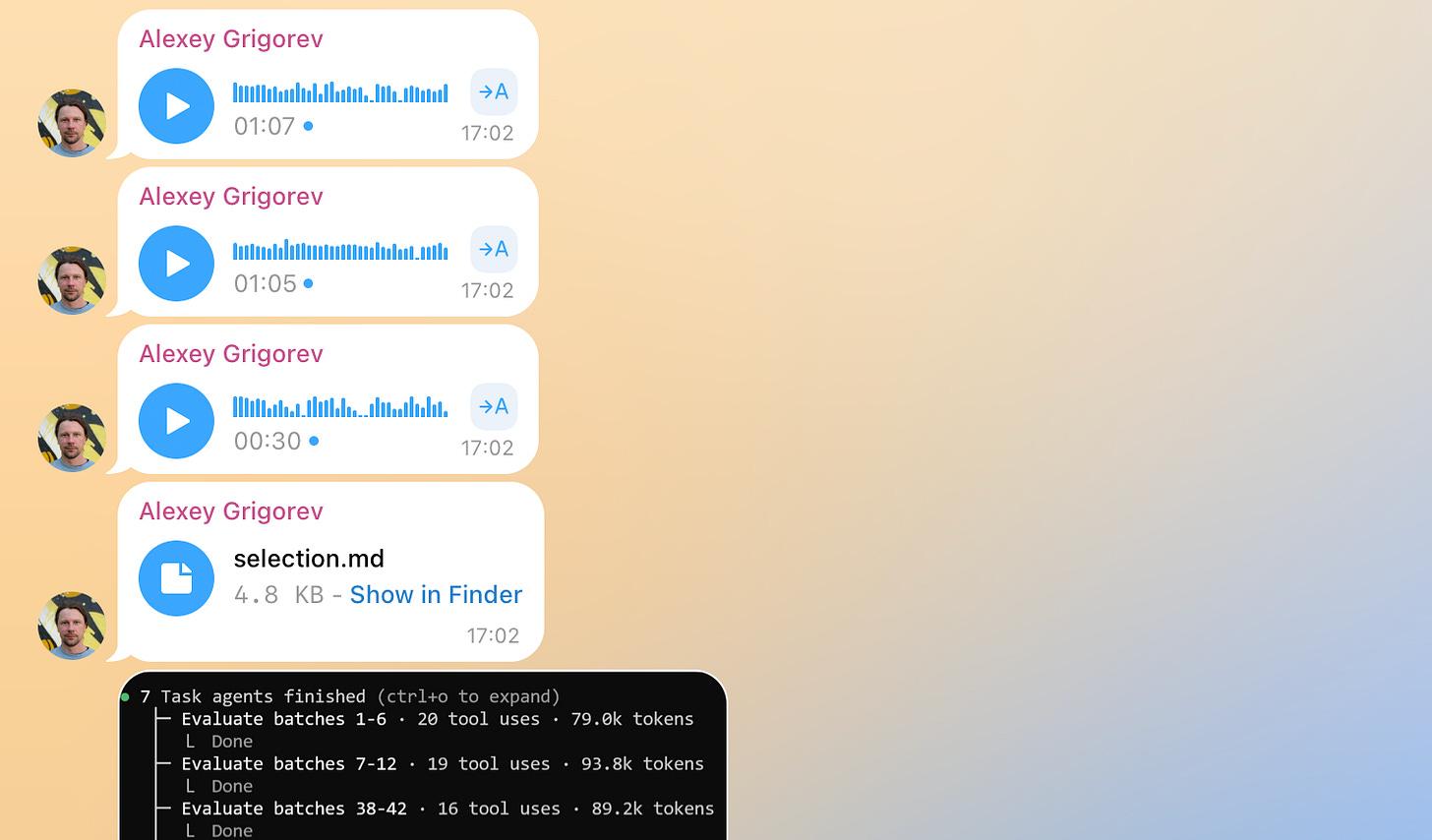
Turning this stream into something structured required rereading, sorting, and stitching everything together by hand. This was slow and mentally expensive.
This is how I started thinking about how to handle an incoming stream of background work so it can be organized and transformed into pieces I could share publicly.
How I Implemented the Telegram Assistant
I had an initial vision for how the assistant should work and decided to iterate on it using ChatGPT.
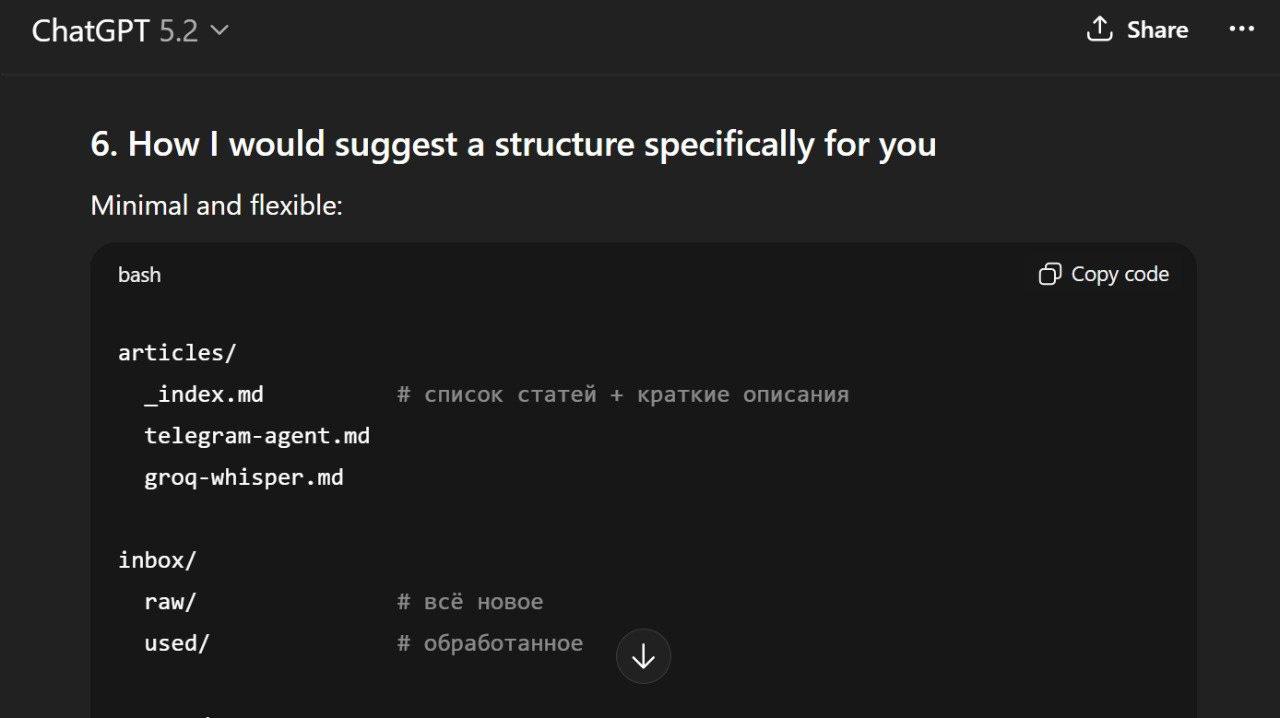
I recorded voice messages, discussed the workflow, and refined the process description until it was clear enough to write down. At the end, I asked ChatGPT to save our conversation as a summary.md file, which became the system specification. It was initially in Russian, but I translated it into English for you.
I usually use ChatGPT to refine my vision before starting any new project. It helps me to better understand what I want to build and how I want to do it.

I didn’t want to implement the system described in summary.md myself. Instead, I asked the Claude Code agent to follow that description and build it. This produced the first working version.
Claude created a Telegram bot that lives in my chat and connected it to a GitHub repository that stores the specification and all subsequent updates from the chat.
I then tested the system by using it as intended: sending messages and recording improvement ideas as voice notes, without leaving the same workflow I was trying to optimize. Claude processed those messages and updated the system.
Here is what the final version looks like.
How the Final Version Works
Telegram Assistant follows this workflow:
1. Capturing

All interaction starts in a Telegram chat. I send text messages, voice notes, images, or files to the bot. Everything is saved locally on my laptop as raw input.
2. Processing
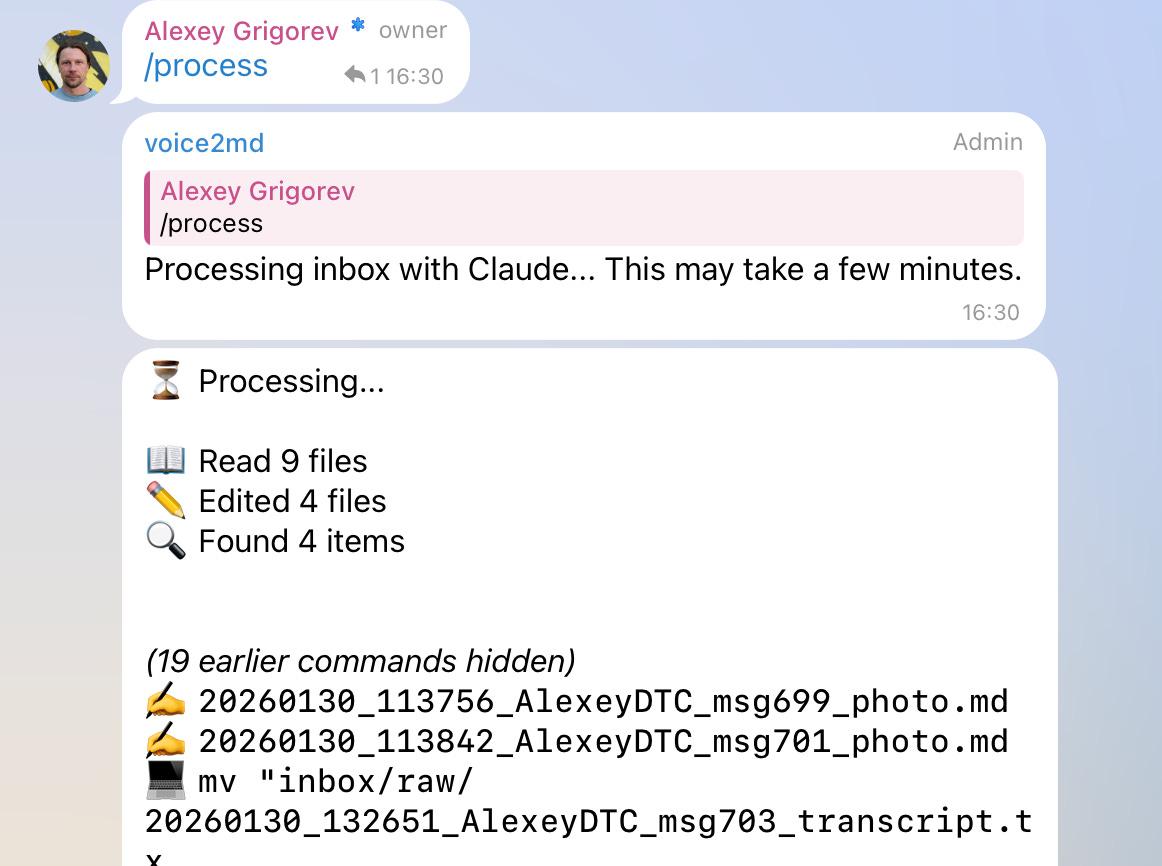
When I run the /process command, the assistant reads all accumulated materials as a batch. For each item, it decides whether the content belongs to an existing article or should start a new one. Articles are updated incrementally rather than regenerated from scratch.
3. Versioning and Feedback
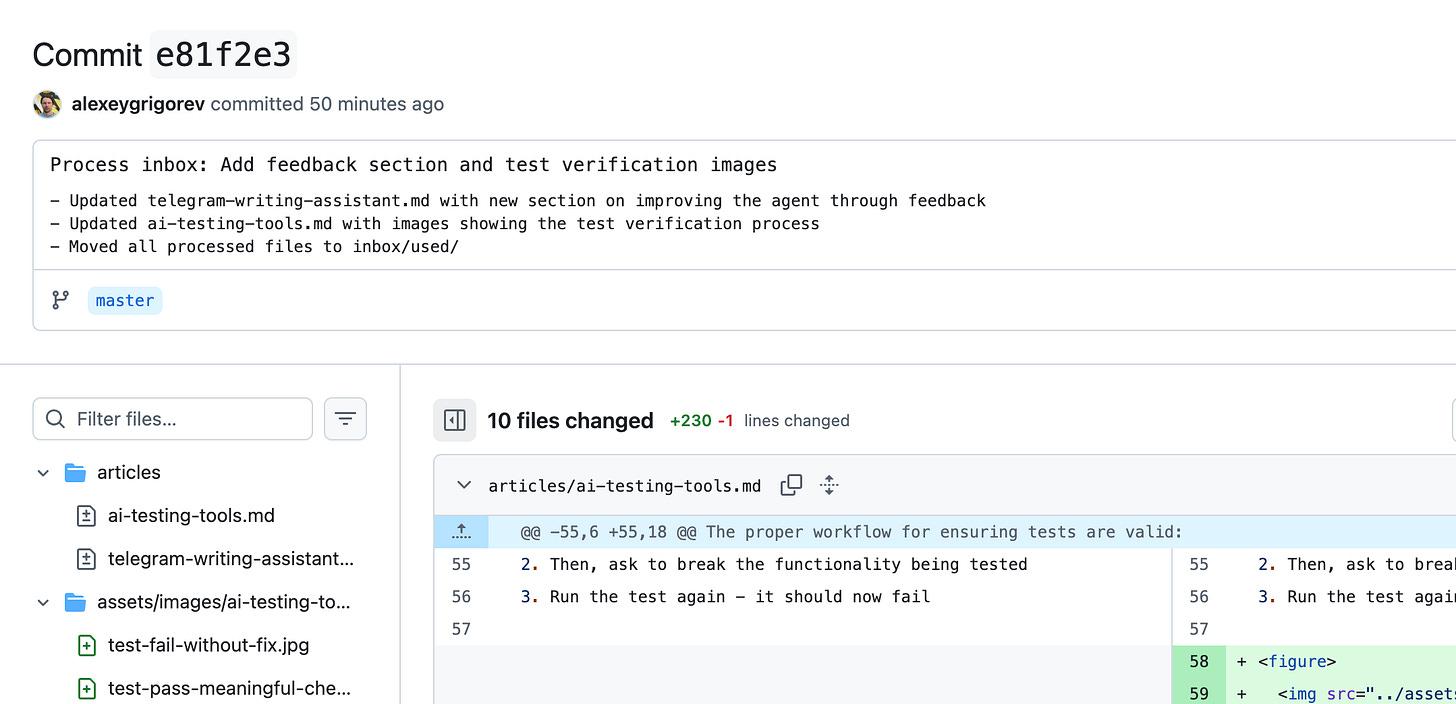
Once processing is complete, all changes are committed to a GitHub repository. The commit is created by the assistant. It shows what it changed and why. The agent also sends a link to the commit back to the Telegram chat.
4. Updating the Configuration

If I need the agent to update its configuration, including the system prompt and the code it’s based on, I can record improvement ideas as voice notes in the same chat. I can also add images if necessary. I then run the /check-tasks command. The assistant processes all the messages in the chat and looks for bug reports, feature suggestions, etc. After that, it updates the prompt or code accordingly, and commits updates to the repository.
Technical Capabilities
The final version of the assistant combines a small set of focused technical capabilities:
1. Voice Transcription
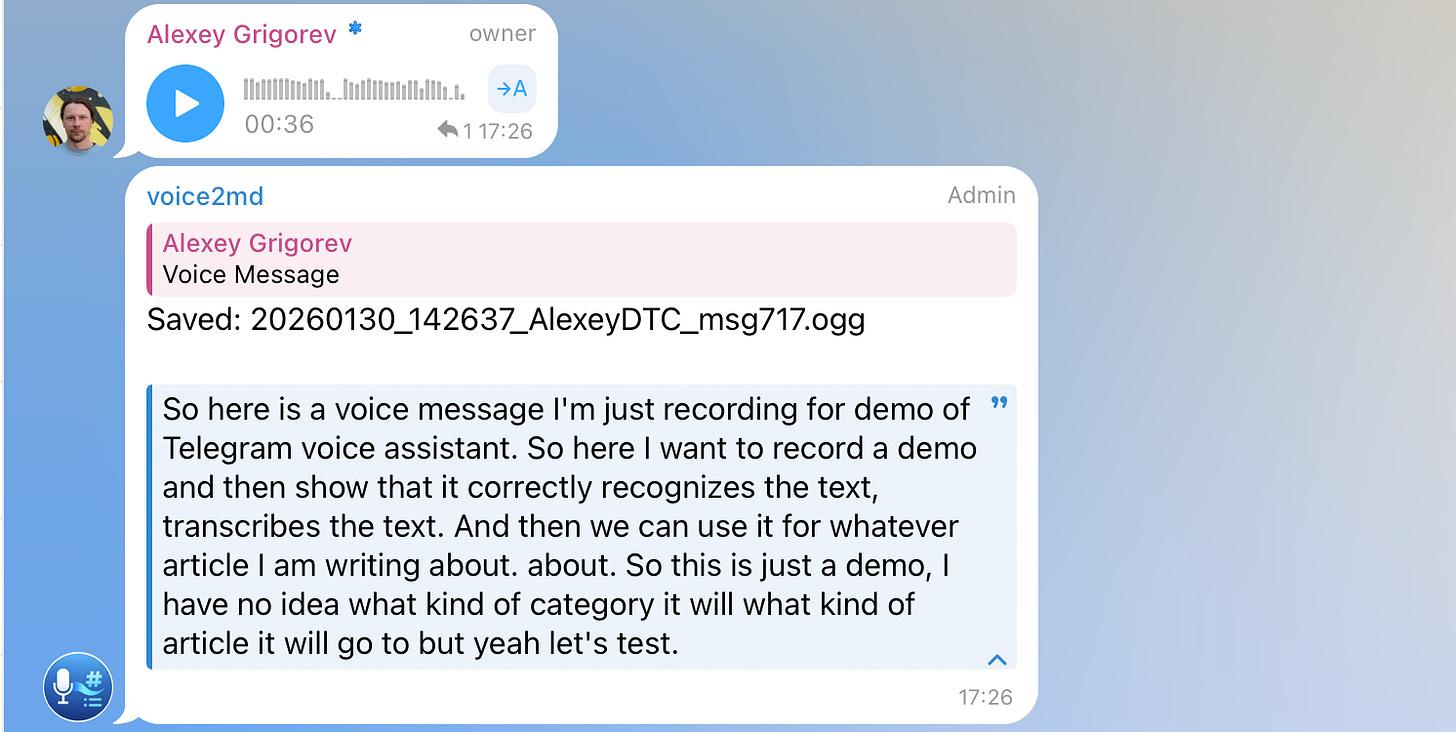
Voice messages are transcribed automatically using Whisper via Groq. After transcription, the original audio files are removed. Only the extracted text is kept and used for further processing. This ensures that all downstream steps operate on text, regardless of how the input was originally captured.
2. Image Processing
Images sent to the bot are processed and described using Groq Vision. Each image is then moved into a structured directory under assets/images/{article_name}/. This makes images first-class inputs that can be referenced in articles rather than remaining as detached chat artifacts.
3. Multilingual Input Handling
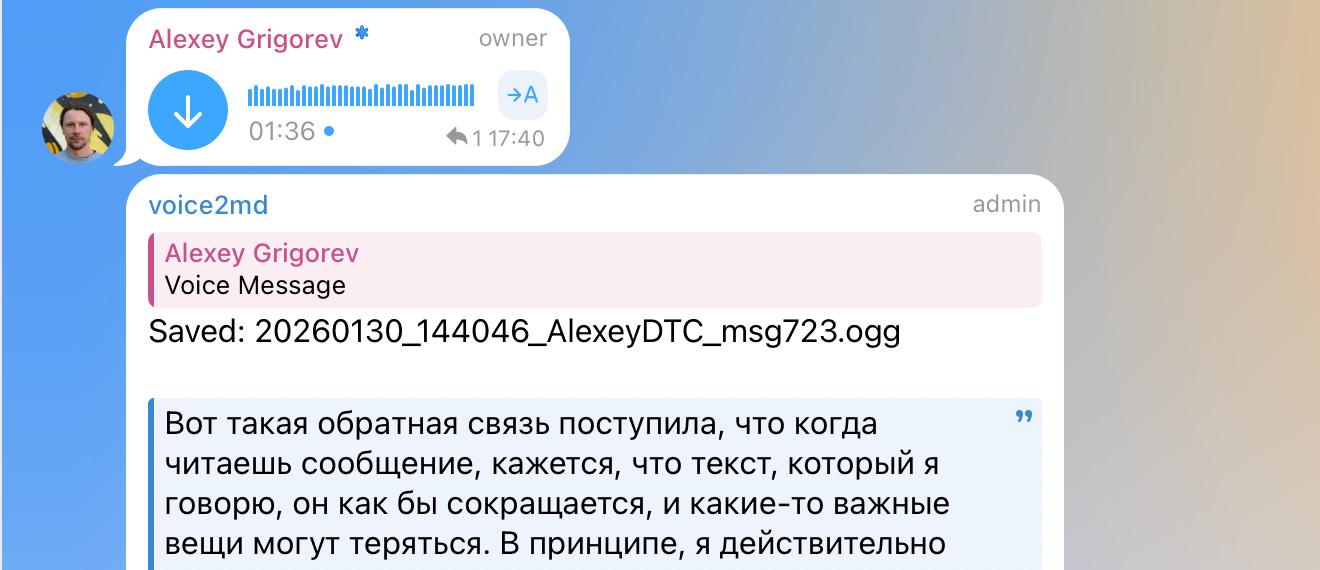
In practice, voice notes are often recorded in Russian, while articles are written in English. During processing, Claude translates all content into English, which is treated as the target language for articles. This removes language constraints from the capture phase.
4. Link Fetching and Summarization
Links dropped into the chat are fetched during processing. Relevant content is summarized and incorporated into the appropriate article, rather than being stored as raw URLs. This keeps external references integrated with the surrounding context.
5. Git-Based Orchestration
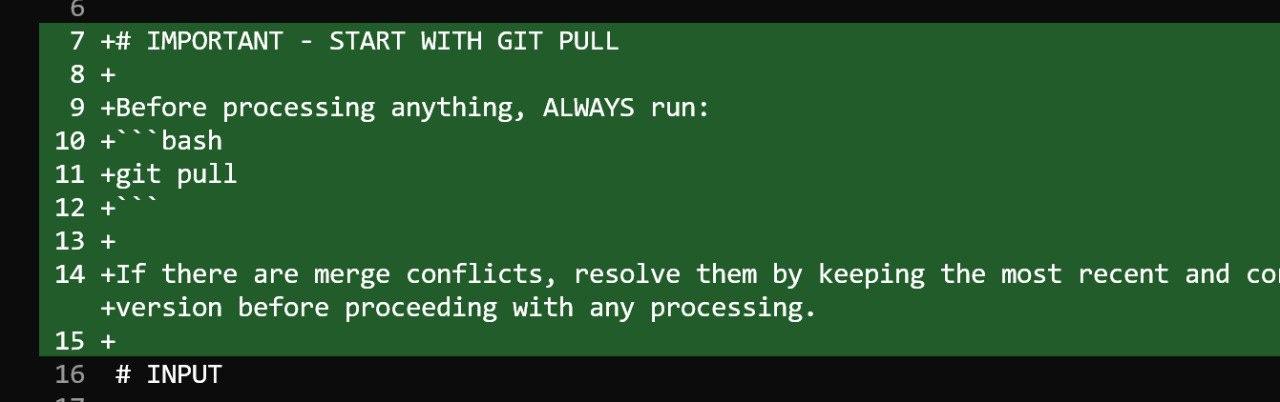
All updates are committed to a GitHub repository. Each processing run results in a concrete diff that shows exactly what changed. The agent can also follow natural-language instructions such as running git pull before processing to ensure it is working with the latest state.
Related content
How I Built a Fully Automated Image-to-Podcast Pipeline for Kids Horror Stories
I built a fully automated system that takes photos of everyday objects and turns them into illustrated horror stories, complete with audio narration and Spotify podcast episodes. …
December 12, 2025
How I Rebuilt My Personal Website in 10 Minutes With AI
I hadn't updated my personal website since 2012. Using AI tools like Lovable and GitHub Copilot, I rebuilt it from scratch in under 10 minutes. Here's exactly how I did it and wha…
December 05, 2025
AI Coding Tools Compared: ChatGPT, Claude, Copilot, Cursor, Lovable and AI Agents
We compare AI coding tools by asking each to help build the same small app, Snake in React. We compare the tools rather than ship one polished build. The walkthrough follows the t…
July 21, 2025