
What Is an AI Engineer? Experience-Based Definition After 15+ Years in Software and ML
A practical definition of the AI engineer role: what they do, how they differ from ML engineers and data scientists, and what it takes to ship AI-powered features from prototype to production.
Over the past year, titles like "AI Engineer" and "GenAI Engineer" have appeared much more frequently on job boards and LinkedIn profiles, but without a commonly accepted definition behind them.
Since I run the AI Engineering Buildcamp, this ambiguity is directly relevant to me and course participants. As the role is being shaped by the market, I decided to conduct my own research on the topic and start an article series where I'll share the insights I've gathered.
Drawing on my experience of around 15 years in software engineering and 12 years building machine learning systems and my conversations with practitioners, I start the series by sharing my view on the AI engineer role.
What is an AI Engineer? My Definition
I consider an AI engineer to be someone responsible for integrating AI into the product. They build and operate AI-powered systems making sure the AI part runs reliably, can be evaluated, and can be maintained and improved over time.
What does an AI Engineer Do?
AI Engineer is usually responsible for:
- Translating product requirements into well-scoped AI problems
- Selecting and integrating appropriate foundation models and tools
- Crafting effective prompts and versioning them
- Defining success metrics and building comprehensive test suites
- Managing deployment, monitoring system performance and handling cost optimization
- Implementing security measures
How Does AI Engineering Relate to ML Engineering and Data Science?
AI engineering shares core production concerns with ML engineering and data science, but its main focus is distinct.
Data scientists are primarily responsible for model creation. They translate business requirements into ML formulations, design and curate training and evaluation datasets, train and test models, and verify that model performance meets expectations prior to deployment.
ML engineers specialize in bringing these models into production: integrating them into backend systems, managing the necessary infrastructure, overseeing deployment and versioning, and ensuring models operate reliably in real-world scenarios.
AI engineers operate in both domains, but with an important distinction: in most contemporary AI applications, the foundational model is a third-party service accessed via an API (such as OpenAI, Anthropic, or Google). This shifts the focus from model development to various engineering tasks, including system integration, prompt design, output structuring, evaluation, and ensuring operational reliability.
Where the AI Engineer Sits in an Organization
The title "AI engineer" can mean very different things depending on an organization's maturity, existing team structure, and technical capabilities. This context shapes both the distribution of responsibilities and the day-to-day focus of the role.
Established ML Teams
In organizations with established ML teams, AI engineering work can take two main forms.
Distribution of Responsibilities
Sometimes, responsibilities are distributed among existing team members. Data scientists expand their scope to include model interaction tasks: learning API specifications, crafting effective prompts and structured inputs, establishing validation criteria, and evaluating system behavior. ML engineers and software engineers take on additional integration responsibilities, designing system architecture, implementing monitoring solutions, and maintaining both legacy systems and new AI-powered features.
In this scenario, team members must balance their usual responsibilities with new AI-related work, often resulting in a substantial increase in workload and a need to rapidly develop skills in unfamiliar areas.
Hiring Dedicated AI Engineers
Alternatively, some organizations delegate these responsibilities to dedicated AI engineers. When this happens, the role becomes more specialized and focused. AI engineers might be embedded within a product engineering team, a centralized AI platform group, or an applied ML team, focusing primarily on integrating and operating AI systems and ensuring their reliability and performance at scale.
Startups and Small Teams
In startups and small teams, the picture is quite different. The AI engineer typically acts as a product-focused generalist. Working closely with product managers and sometimes directly with end users, they rapidly prototype AI-powered features, implement backend logic, and occasionally handle frontend components. Since teams are small, the boundaries between product engineering, ML work, and infrastructure are less rigid, and the same person may shepherd a feature from initial experimentation through production hardening once its value is proven. This requires a high degree of flexibility and ownership, with responsibilities shifting as the product's needs evolve.
The following sections will use the startup context to further illustrate the AI engineer’s work.
What an AI Engineer Does: A Simple Example
Imagine a web interface for an online classifieds website called "Simple Sell" where you can upload a photo of an item and the system auto-fills the listing title, description, category, and price suggestion.
Creating the Prototype
I built the website interface of such a marketplace using Lovable with just one prompt. This gives us a foundation for the example. While frontend development is not usually the concern of AI engineers, they may sometimes need to implement frontend changes, especially in smaller teams.
The prompt was:
{% prompt %} Create an online classifieds platform where people can create and see things to buy and sell. It will be very simplistic - a list page with products, a create page where we create a listing (title, description, categories, and a place to upload a single image). Plus there's a contact button that currently doesn't do anything. The listings come from API (mock it for now) and when we save the event, it also saves into the API. We also pre-fill the details with AI. The posting flow: first they ask for the image, you upload, and then you see the form with all pre-filled information from the image. All the API interactions are in a single file.
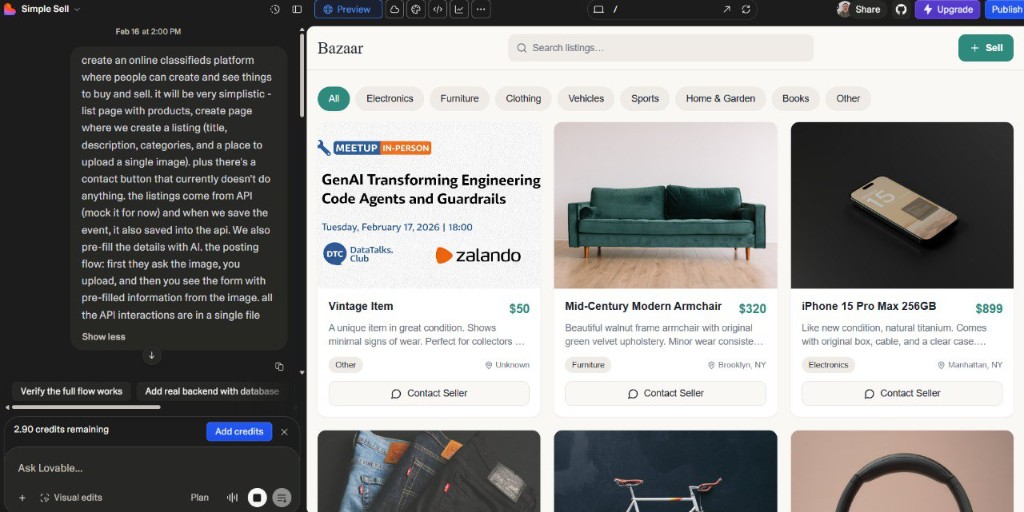
With a second prompt, I asked Lovable to rename the website and switch to EUR pricing.
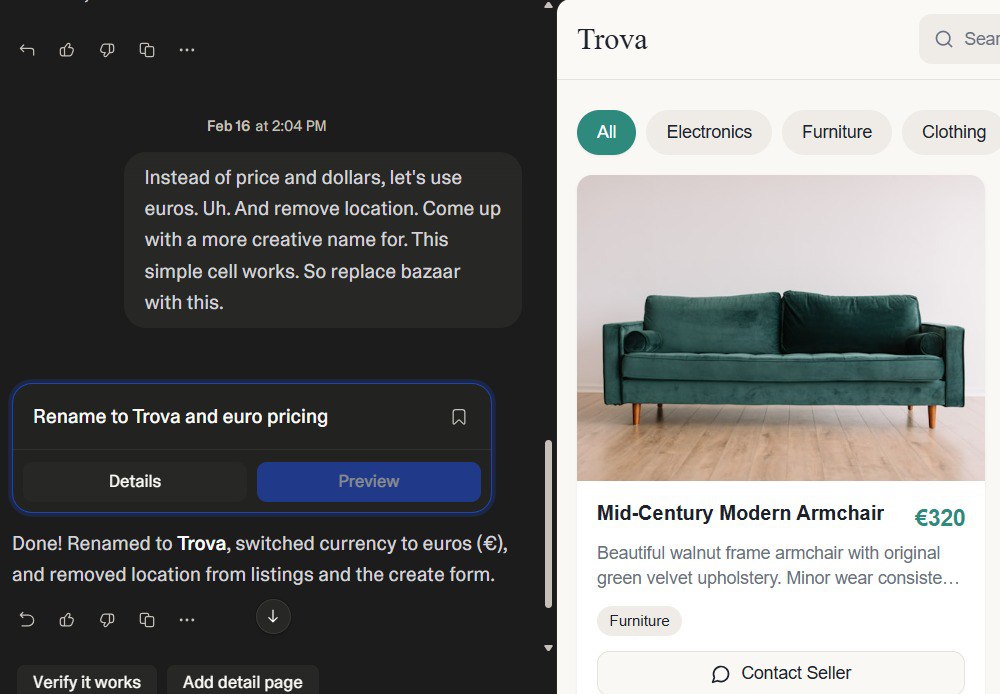
The GitHub repository for this project is called simple-sell; the site itself is called Trova. I'll use Trova when referring to the running application throughout the rest of the example.
With the prototype in place, we have a foundation to work with.
Adding Backend Support
This is where the AI engineer's work usually starts. When there is a frontend, an AI engineer needs to add backend support to it.
In my case, I decided to delegate this task to Claude Code. I exported the code from Lovable and asked Claude Code to build a simple FastAPI backend with two endpoints: one to add a listing, and one to pre-fill listing details from an image via AI.
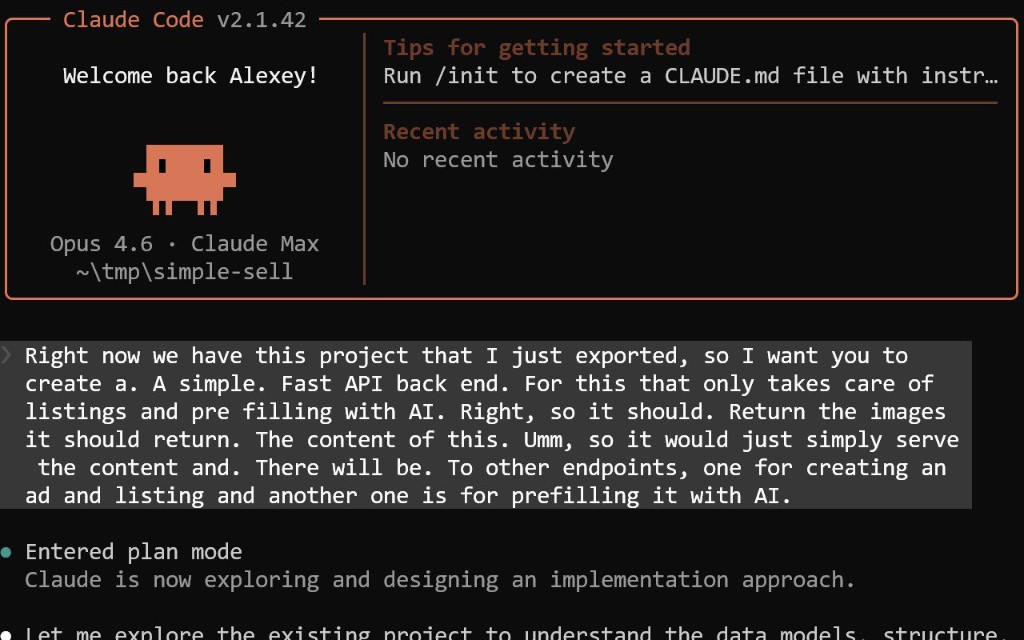
First Pass: Testing the Flow and Adjusting the Prompt
The first thing an AI engineer does after the backend is wired up is run the system with a real input and look at the output. For example, uploading a photo of headphones to see what the LLM returns. The LLM might return something like "Comfortable wired headphones - experience crisp sound quality and comfort."
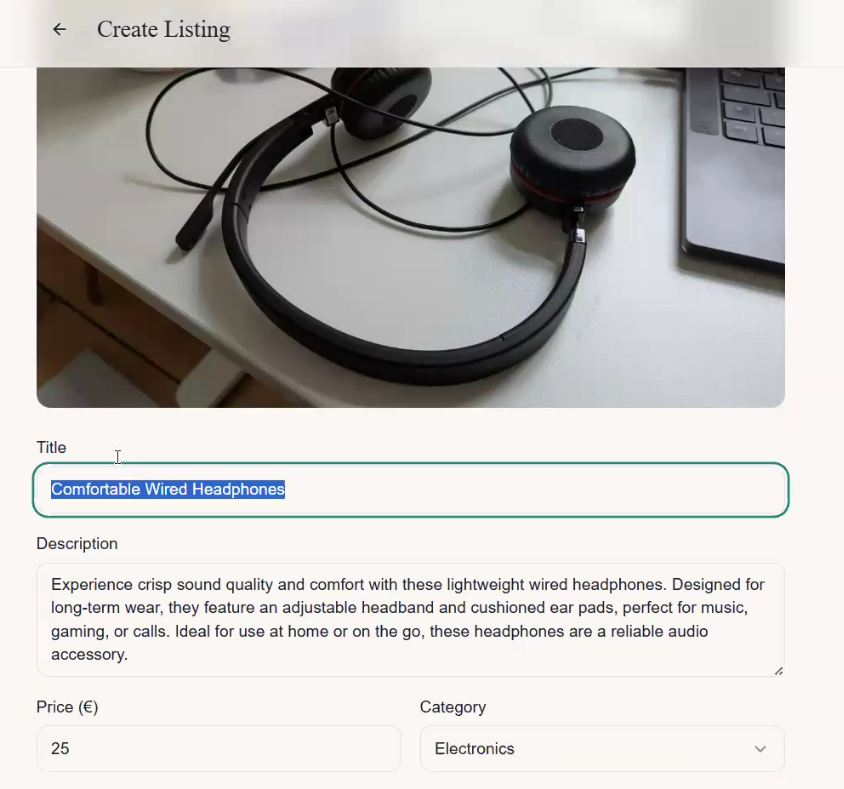
That reads like marketing copy. For a classifieds site, the tone should be more casual: "Comfortable headphones, barely used, get them while they last." The original system prompt had no instructions about tone or audience, so the model defaulted to generic product-description style. The AI engineer updates it to specify the context: a peer-to-peer marketplace, casual tone, concise titles.
Here is the updated prompt after that first adjustment:
class AIAnalysisResult(BaseModel):
title: str
description: str
category: str
price: float
SYSTEM_PROMPT = f"""
You are an assistant that analyzes images of items for
a marketplace listing.
Given an image, suggest:
- A concise, appealing title
- A detailed description (2-3 sentences)
- A category from this list: {", ".join(CATEGORIES)}
- A fair price in euros
""".strip()
async def analyze_image_with_ai(image_bytes: bytes) -> AIAnalysisResult:
client = AsyncOpenAI()
b64 = base64.b64encode(image_bytes).decode("utf-8")
messages = [
{"role": "system", "content": SYSTEM_PROMPT},
{"role": "user", "content": [
{"type": "input_image",
"image_url": f"data:image/jpeg;base64,{b64}",
"detail": "low"},
{"type": "input_text",
"text": "Analyze this item for a marketplace listing."},
]},
]
response = await client.responses.parse(
model="gpt-4o-mini",
input=messages,
text_format=AIAnalysisResult,
)
return response.output_parsed
You may think that this is it: the solution is working and the platform should be ready with this AI feature. But defining a Pydantic class and calling the API is only the start. Turning this API call into a product feature takes more work.
AI Engineering Work: The Systematic Approach
That first prompt iteration is a good start, but it is just one pass. Getting a feature like this to production and keeping it working requires a more disciplined approach. Here is what an AI engineer needs to do:
-
Test the prompt so the model behaves as intended. Add a test that sends an image and asserts on the output (test_ai.py).
-
Build a set of test images, run the extraction pipeline on them, and check the outputs. That gives you a metric of how well the model is doing.
-
Iterate on the prompt and re-run the evaluation set to catch regressions before they reach users.
-
Roll out gradually with A/B testing and release to a small fraction of users first. Watch for regressions so the experience stays good.
-
Build and run a monitoring dashboard that tracks failures: how often the endpoint returns nothing or errors.
-
Log inputs and outputs so you can inspect misalignments, debug issues, and understand what the model is doing in production.
-
Have human annotators periodically sample from the monitoring pipeline and check quality. Problematic cases from production can be added to the evaluation set.
-
Check for model upgrades and run the same evaluation set to spot any changes in performance.
-
Version prompts and track experiments. Use an experimentation system (e.g. MLflow or Git) to keep track of what changed—prompt, tools, or model—and what the impact was.
-
Collect user feedback explicitly (e.g. thumbs up/down) and implicitly (e.g. when users correct the output). Use it to improve prompts and evaluation sets.
Even in this minimal example, all of this matters.
Other Tasks
CI/CD
CI/CD for AI systems has an extra dimension compared to standard software pipelines. Beyond running unit tests on push, it means running your evaluation set against every prompt or model change before it reaches production, and blocking deploys when eval scores drop below a threshold. In a staging environment, the AI pipeline should run against known inputs and assert on the outputs.
An AI engineer typically does not own the CI/CD infrastructure alone, platform or DevOps engineers often do, but knowing how to wire an eval run into a pipeline is a distinct and important skill. In a startup, being able to set this up yourself is a real advantage.
For this example, Claude Code built the tests (test_listings.py, test_ai.py) and the CI/CD pipeline (test-backend.yml).
Frontend
The frontend may also need updates to call the backend, show loading states, and handle errors gracefully. In larger organizations, frontend engineers own this. At a startup, it often falls to the AI engineer—and with tools like Claude Code, you don't need to be a TypeScript expert to wire it up.
More Complex Scenarios: Retrieval-Augmented Generation (RAG) and Agentic Systems
So far we've stayed with the simplest shape of an AI feature: a single backend endpoint that calls an LLM with a prompt and returns a response.
In real products, teams quickly ask for "something smarter": the system should use internal data, combine multiple steps, or even take actions on behalf of the user. For Trova, that might mean adding RAG so the system retrieves similar listings to suggest a competitive price, or adding an agent that can automatically post the draft listing once the user confirms the details. From an AI engineer's perspective, both mean moving from a one-box flow to richer architectures, and taking on significantly more design, implementation, and operations work.
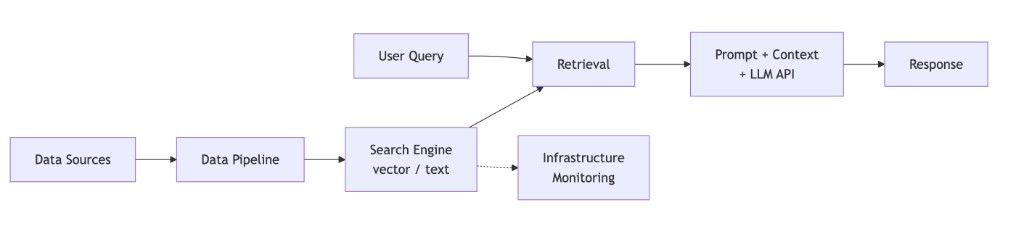
The Trova image-prefill feature is a good example of the simplest shape: a user action triggers a backend call, the backend calls the LLM API once with a prompt, and returns the result. The diagram below makes this structure explicit before we see what changes when things get more complex.

Now let's see what happens to the AI engineer's work when we move to RAG and then to agentic systems.
Retrieval-Augmented Generation (RAG)
When retrieval-augmented generation (RAG) is introduced, the AI system expands from a single model call into a multi-component architecture.
The AI engineer should design and operate a full retrieval layer that feeds the model with relevant context. This includes ownership of:
-
Data selection and ingestion strategy: Deciding which sources are authoritative and relevant, defining how they are cleaned and normalized, and ensuring they are transformed into an indexable representation suitable for retrieval.
-
Index and retrieval design: Choosing the retrieval approach (vector, lexical, hybrid), defining chunking strategy, metadata schema, embedding configuration, and relevance filtering. These decisions directly affect answer quality.
-
Retrieval orchestration: Designing the retrieval workflow that translates user queries into search operations, ranks and filters candidates, and constructs a bounded context payload that fits model constraints.
-
Prompt and context integration: Ensuring retrieved context is injected into the prompt in a structured and controlled way, with clear instructions to mitigate hallucination and misuse of retrieved content.
-
Reliability and failure handling: Defining behavior when retrieval is slow, empty, stale, or partially failing. Latency budgets, fallbacks, and degradation strategies become part of system design.
-
End-to-end evaluation: Extending evaluation beyond generation quality to include retrieval accuracy. This includes relevance metrics, offline evaluation sets, regression testing, and measuring whether retrieval materially improves outcomes.
-
Monitoring and lifecycle management: Monitoring index freshness, retrieval quality, latency, and cost. Planning re-indexing, embedding upgrades, and scaling strategies as data and traffic evolve.
Visually, you can think of RAG like this:
Agentic Systems
Agentic systems push this one step further. Instead of a single LLM call with retrieved context, the AI engineer designs an orchestration loop where the model can call tools (APIs), observe results, and decide what to do next.
Even though the diagram may look simple, every new box represents additional systems work: more code paths, more failure modes, more evaluation, more monitoring.
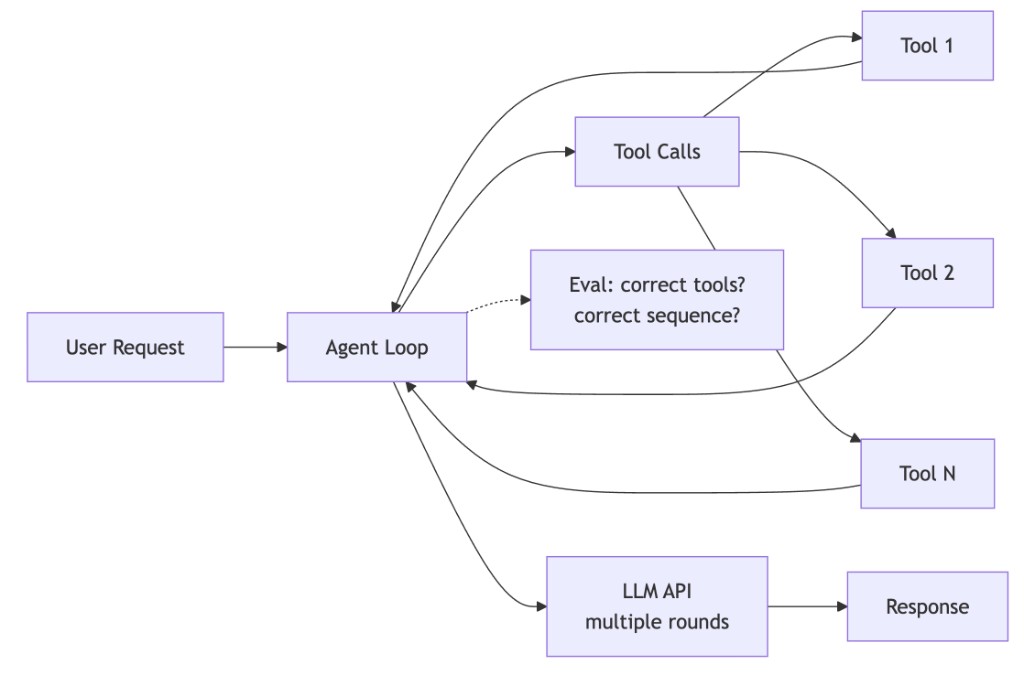
From the AI engineer's point of view, building an agentic system usually involves:
- Defining tools as real APIs: Working with product and backend teams to decide which actions the agent can take (e.g. "get listing", "create listing", "update price"), and exposing them as stable, well-documented APIs with clear contracts and permissions.
- Wrapping tools for the model: Describing each tool's inputs, outputs, and behavior in a form the model can use (tool schemas, OpenAPI, or function-calling definitions), and adding validation so malformed tool calls do not crash the system.
- Designing the agent loop: Implementing the control logic that orchestrates the agent's behavior. This includes limits on the number of steps, timeouts, and clear stopping conditions.
- Adding guardrails and constraints: Encoding business rules (what the agent is allowed to do), safety checks, and prompts that keep the agent on-task and within policy, especially when tools can change data or trigger external actions.
- Testing tools and behaviors: Writing tests for each tool and for multi-step behaviors.
- Instrumenting and monitoring: Logging full traces of agent runs (prompts, tool calls, responses), tracking cost, latency, failure modes, and tool misuse, and using these traces to debug and iterate.
- Operating and evolving the system: Rolling out new tools, updating prompts, and upgrading models while guarding against regressions in behavior, reliability, or safety.
Taken together, across all three patterns—single LLM call, RAG, and agentic systems—the work involves turning AI capabilities into product systems that run reliably. The surface area grows with each level of complexity, but the underlying concerns—scoping, evaluation, monitoring, and iteration—remain consistent.
Conclusion
The examples in this article span a wide range, from a single LLM call to a full agentic system, but the pattern is consistent. In each case, the key part is the engineering work: how the problem is scoped, how quality is measured, how changes are deployed, and how the system is kept running.
The role is still being defined in real time. I've been collecting real AI engineer job postings and take-home interview assignments to understand how the market is defining the role. If you want to follow the research and get updates about the next article in the series, subscribe at alexeyondata.substack.com.
Related content
What Is an AI Engineer? 2026 Role, Skills and Responsibilities Based on 1,000+ Job Descriptions
Learn what an AI engineer is in 2026: responsibilities, skills, tools, and real-world use cases based on analysis of 1,000+ AI engineer job descriptions.
March 04, 2026
Tailor Your CV for AI Engineering Roles
In this workshop we take a CV that's not focused on AI engineering roles and make it more relevant. We build a pipeline where: a renderer turns YAML into Harvard-style CVs we take…
July 8, 2026
Tailor Your CV for AI Engineering Roles
In this workshop we take a CV that's not focused on AI engineering roles and make it more relevant. We build a pipeline where: a renderer turns YAML into Harvard-style CVs we take…
July 08, 2026